0x00
偏硬件的部分就不赘述了,毕竟基本过时了。
0x01 idle 线程 和 thread_yield()
还记得在此前的 cpu 任务调度函数中
1
2
3
4
5
6
| void task_schedule(void)
{
ASSERT(!list_empty(&thread_ready_list));
}
|
这里断言就绪队列不为空。
但是我们这里硬盘驱动必然要和硬盘设备打交道,必然会等待硬盘IO,等待的时候不可能一直占用 cpu,此时就会阻塞自己调度其他线程。在 kernel 主线程初始化硬盘的时候,等待硬盘IO时阻塞自己,然而此时没有其他线程,这不就出问题了?
此前因为没有 kernel 主线程阻塞自己的场景,才有这个断言。后续必然会有类似场景,所有线程都未就绪,此时必须要设置一个“兜底”的线程,让 cpu 休息,而不是空转。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
static void idle(void* arg)
{
(void)arg;
while(1)
{
thread_block(TASK_BLOCKED);
asm volatile ("sti\n\thlt" : : : "memory");
}
}
void task_schedule(void)
{
thread_tag = NULL;
if(list_empty(&thread_ready_list)) thread_unblock(idle_thread);
}
void _init_thread(void)
{
print("init thread start\n");
list_init(&thread_ready_list);
list_init(&thread_all_list);
lock_init(&pid_lock);
make_main_thread();
idle_thread = thread_create("idle", 10, idle, NULL);
print("init thread done\n");
}
|
这样平时 idle 线程始终调用thread_block(TASK_BLOCKED);阻塞自己,不怎么影响性能,而到了没有其他线程的情况下就唤醒这个闲逛进程,往下执行asm volatile ("sti\n\thlt" : : : "memory");来休息 cpu。
另外增加一个线程主动让出 cpu 的函数
1
2
3
4
5
6
7
8
9
10
11
|
void thread_yield(void)
{
struct _task_struct* cur_thread = running_thread();
_intr_status old_status = _disable_intr();
ASSERT(!elem_find(&thread_ready_list, &cur_thread->general_tag));
list_append(&thread_ready_list, &cur_thread->general_tag);
cur_thread->status = TASK_READY;
task_schedule();
_set_intr_status(old_status);
}
|
0x02 硬盘驱动
大多是代码实现。先看基本数据结构类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| #ifndef __DEVICE_IDE_H
#define __DEVICE_IDE_H
#include "stdint.h"
#include "kernel/list.h"
#include "kernel/bitmap.h"
#include "sync.h"
struct partition{
uint32_t start_lba;
uint32_t sec_cnt;
struct disk* my_disk;
struct list_elem part_tag;
char name[8];
struct super_block* sb;
struct bitmap block_bitmap;
struct bitmap inode_bitmap;
struct list open_inodes;
};
struct disk{
char name[8];
struct ide_channel* my_channel;
uint8_t dev_no;
struct partition prim_parts[4];
struct partition logic_parts[8];
};
struct ide_channel{
char name[8];
uint16_t port_base;
uint8_t irq_no;
struct lock lock;
bool expection_intr;
struct semaphore disk_done;
struct disk devices[2];
};
void _init_ide(void);
void ide_read(struct disk* hd, uint32_t lba, void* buf, uint32_t sec_cnt);
void ide_write(struct disk* hd, uint32_t lba, void* buf, uint32_t sec_cnt);
void _hd_intr_handler(uint8_t irq_no);
#endif
|
重点说说有关并发处理和硬盘中断处理。
可以看到 struct ide_channel 有两个成员,struct lock lock; 和 struct semaphore disk_done;。之所以要锁,自然是因为一个通道同时只能有一个线程读写。
我们设计的互斥锁,本质保护的是代码,保证某部分代码同时只有一个线程执行,这样锁住读写硬盘通道的代码,自然保证其并发安全。
然而,如果只使用互斥锁,以 ide_read() 为例子
1
2
3
4
5
6
7
8
9
10
| void ide_read(...) {
lock_acquire(&channel->lock);
select_disk(hd);
set_sector_args(...);
send_cmd(READ);
while(硬盘忙) { }
}
|
硬盘忙的时候只能占着 cpu 忙等,如果想要 thread_yield 或者 thread_block 来让出 cpu,此时又持有锁,如果直接这样阻塞,未来想要唤醒这个阻塞的线程,怎么找得到呢?毕竟在硬盘中断处理程序中,它并不会知道哪个线程在持锁阻塞等待硬盘IO。
这个时候就要使用信号量操作了。再放一次信号量操作代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
struct semaphore{
uint8_t value;
struct list waiters;
};
void sema_down(struct semaphore* psema)
{
_intr_status old_status = _disable_intr();
while(psema->value == 0)
{
ASSERT(!elem_find(&psema->waiters, &running_thread()->general_tag));
if(elem_find(&psema->waiters, &running_thread()->general_tag))
{
PANIC("sema_down: thread blocked has been in waiters_list\n");
}
list_append(&psema->waiters, &running_thread()->general_tag);
thread_block(TASK_BLOCKED);
}
psema->value--;
ASSERT(psema->value == 0);
_set_intr_status(old_status);
}
void sema_up(struct semaphore* psema)
{
_intr_status old_status = _disable_intr();
ASSERT(psema->value == 0);
if(!list_empty(&psema->waiters))
{
struct _task_struct* thread_blocked = elem2entry(struct _task_struct, general_tag, list_pop(&psema->waiters));
thread_unblock(thread_blocked);
}
psema->value++;
ASSERT(psema->value == 1);
_set_intr_status(old_status);
}
|
可以看到,信号量本身可以记录哪些线程在等待资源(waiters 队列,可以多线程等待),同时可以记录资源的量(也就是信号量的值 value)。
还是以 ide_read 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
void ide_read(struct disk* hd, uint32_t lba, void* buf, uint32_t sec_cnt)
{
ASSERT(lba <= max_lba);
ASSERT(sec_cnt > 0);
lock_acquire(&hd->my_channel->lock);
select_disk(hd);
uint32_t secs_op;
uint32_t secs_done = 0;
while(secs_done < sec_cnt)
{
if((secs_done + 256) <= sec_cnt)
{
secs_op = 256;
}else{
secs_op = sec_cnt - secs_done;
}
set_sector_args(hd, lba + secs_done, secs_op);
send_cmd_to_channel(hd->my_channel, CMD_READ_SECTOR);
sema_down(&hd->my_channel->disk_done);
if(!busy_wait(hd))
{
char error[64];
sprintf(error, "%s read sector %d failed !!!!\n", hd->name, lba);
PANIC(error);
}
read_from_sector(hd, (void*)((uint32_t)buf + secs_done * 512), secs_op);
secs_done += secs_op;
}
lock_release(&hd->my_channel->lock);
}
|
这里在向硬盘发送命令后,调用 sema_down(&hd->my_channel->disk_done); ,将自己阻塞。
此时 cpu 可以执行其他的不涉及这个硬盘读写的线程,或者是单纯执行此前设计的闲逛线程。
当硬盘完成,发送硬盘中断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void _hd_intr_handler(uint8_t irq_no)
{
ASSERT(irq_no == 0x2e || irq_no == 0x2f);
uint8_t ch_no = irq_no - 0x2e;
struct ide_channel* channel = &channels[ch_no];
ASSERT(channel->irq_no == irq_no);
if(channel->expection_intr)
{
channel->expection_intr = false;
sema_up(&channel->disk_done);
inb(reg_status(channel));
}
}
|
这里通过 channel->expection_intr 判断是否是预期的中断,然后调用 sema_up(&channel->disk_done);,唤醒在等待此次 IO 的线程。
其他代码实现就不放了。
0x03 测试
main.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| #include "init.h"
#include "debug.h"
#include "stdtype.h"
#include "interrupt.h"
#include "memory.h"
#include "thread.h"
#include "console.h"
#include "kernel/print.h"
#include "keyboard.h"
#include "kernel/ioqueue.h"
#include "process.h"
#include "user/syscall.h"
#include "syscall-init.h"
#include "stdio.h"
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int main(void)
{
print("kernel made by r3t2\n");
init();
process_execute(u_prog_a, "user_prog_a");
process_execute(u_prog_b, "user_prog_b");
thread_create("testA", 31, k_thread_a, NULL);
thread_create("testB", 31, k_thread_b, NULL);
_enable_intr();
while(1);
return 0;
}
void k_thread_a(void* arg)
{
(void)arg;
void* p1 = sys_malloc(0x100);
void* p2 = sys_malloc(0x101);
void* p3 = sys_malloc(0x450);
printf(" thread_a malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(p1);
sys_free(p2);
sys_free(p3);
while(1);
}
void k_thread_b(void* arg)
{
(void)arg;
void* p1 = sys_malloc(0x100);
void* p2 = sys_malloc(0x101);
void* p3 = sys_malloc(0x450);
printf(" thread_b malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(p1);
sys_free(p2);
sys_free(p3);
while(1);
}
void u_prog_a(void)
{
void* p1 = malloc(0x100);
void* p2 = malloc(0x101);
void* p3 = malloc(0x450);
printf(" prog_a malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(p1);
free(p2);
free(p3);
while(1);
}
void u_prog_b(void)
{
void* p1 = malloc(0x100);
void* p2 = malloc(0x101);
void* p3 = malloc(0x450);
printf(" prog_b malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(p1);
free(p2);
free(p3);
while(1);
}
|
硬盘驱动和相关初始化已经加入了 init() 函数中。
再准备一块虚拟硬盘,设置好分区、大小等信息,qemu 挂载运行。
1
| qemu-system-i386 -hda vdisk.img -hdb vdisk2.img
|
测试如下
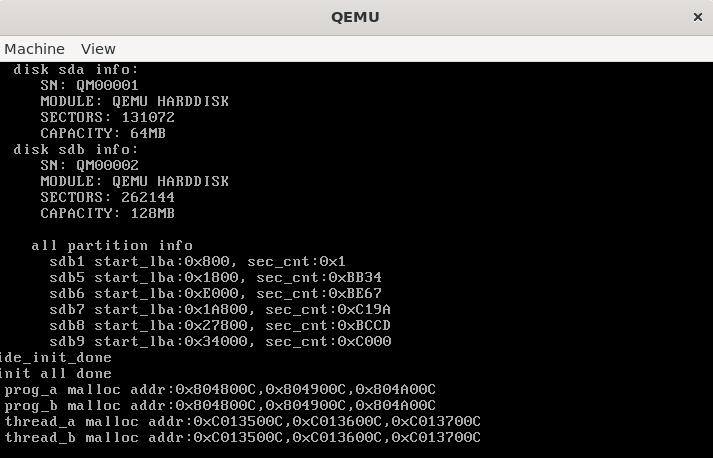
正常符合预期。


