0x00
实现系统调用的基本接口,以及完善了内存管理
0x01 系统调用
此前实现了用户进程,但是发现用户进程困于权限很多事都做不到。以输出为例,在进入保护模式后,写显存只有操作系统能做,用户进程不能做,但又不能直接更改用户的权限。那么一个很显然的办法就是由操作系统来帮助用户进行输出。
操作系统怎么帮助用户程序呢?这就需要 系统调用 了。
系统调用就是让用户进程申请操作系统的帮助,让操作系统帮其完成某项工作,也就是相当于用户进程调用了操作系统的功能,因此“系统调用”准确地来说应该被称为“操作系统功能调用”。
由操作系统来提供这样一组受控的接口,既防止用户进程滥用操作系统能力,又能够方便的帮助用户进程做很多事情,既有安全性,又有可用性,何乐而不为?
那么如何实现系统调用机制呢?既然要使用操作系统功能自然要提升到 ring0 内核态,此前 有介绍过处理器只有通过“门结构”才能由低特权级转移到高特权级。为了方便实现和保证安全,操作系统可以利用软中断机制作为系统调用的入口。但通常所有系统调用共享一个统一入口,在进入内核后根据系统调用号分发到具体的处理函数
创建好 0x80 中断描述符,给系统调用
1
2
3
4
5
6
7
8
9
10
11
|
static void _init_IDT(void)
{
for(int i = 0; i < IDT_DESC_CNT; i++)
{
_make_IntrDesc(&IDT[i], IDT_DESC_ATTR_DPL0, _intr_entry_table[i]);
}
_make_IntrDesc(&IDT[IDT_DESC_CNT-1], IDT_DESC_ATTR_DPL3, syscall_handler);
print("init IDT done\n");
}
|
其中断处理函数功能是根据系统调用号路由到不同的处理程序中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| ; ============= 0x80号中断,系统调用
[bits 32]
extern syscall_table
section .text
global syscall_handler
syscall_handler:
; ========= 保存上下文环境, 和中断栈格式一致
push 0
push ds
push es
push fs
push gs
pushad
push 0x80
; ======== 为系统调用子功能传入参数
push edx ; ARG_3
push ecx ; ARG_2
push ebx ; ARG_1
; ======== 调用对应系统调用
call [syscall_table + eax*4]
add esp, 12 ;跨过上面的三个参数
; ========= 将call调用后的返回值存入当前内核栈中的eax的位置
mov [esp + 8*4], eax
jmp intr_exit ;恢复上下文
|
然后定义好系统调用表 syscall_table, 里面注册好在内核中各个系统调用的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #define syscall_nr 32
typedef void* syscall;
syscall syscall_table[syscall_nr];
uint32_t sys_getpid(void)
{
return running_thread()->pid;
}
uint32_t sys_write(char* str)
{
console_put_str(str);
return strlen(str);
}
void _init_syscall(void)
{
print("syscall_init_start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
syscall_table[SYS_MALLOC] = sys_malloc;
syscall_table[SYS_FREE] = sys_free;
print("_init_syscall done\n");
}
|
最后定义好对用户进程的接口即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| #include "syscall.h"
#define _syscall0(NUMBER) ({ \
int retval; \
asm volatile( \
"int $0x80" \
: "=a"(retval) \
: "a"(NUMBER) \
: "memory" \
); \
retval; \
})
#define _syscall1(NUMBER, ARG_1) ({ \
int retval; \
asm volatile( \
"int $0x80" \
: "=a"(retval) \
: "a"(NUMBER), "b"(ARG_1) \
: "memory" \
); \
retval; \
})
#define _syscall2(NUMBER, ARG_1, ARG_2) ({ \
int retval; \
asm volatile( \
"int $0x80" \
: "=a"(retval) \
: "a"(NUMBER), "b"(ARG_1), "c"(ARG_2) \
: "memory" \
); \
retval; \
})
#define _syscall3(NUMBER, ARG_1, ARG_2, ARG_3) ({ \
int retval; \
asm volatile( \
"int $0x80" \
: "=a"(retval) \
: "a"(NUMBER), "b"(ARG_1), "c"(ARG_2), "d"(ARG_3) \
: "memory" \
); \
retval; \
})
uint32_t getpid()
{
return _syscall0(SYS_GETPID);
}
uint32_t write(char* str)
{
return _syscall1(SYS_WRITE, str);
}
void* malloc(uint32_t size)
{
return (void*)_syscall1(SYS_MALLOC, size);
}
void free(void* ptr)
{
_syscall1(SYS_FREE, ptr);
}
|
0x02 完善内存管理
此前仅有以页为单位的内存申请,但是却没有更细化的内存管理,以及内存释放也没有实现。
内存管理的具体机制在 此前 已经记录,不再赘述。内存的释放也就是回收不再被使用的内存,以便于下次利用。粗浅理解基本上是内存申请的逆操作,但还是有许多细节问题。
申请的大概流程是
- 查找虚拟内存池位图获取可用虚拟页, 标记为已使用
- 查找物理内存池位图获取可用物理页,标记为已使用
- 逐页映射虚拟地址与物理页,也就是在页表各项填入对应物理地址
那么释放就是
- 找到对应的物理页,在物理内存池位图中标记为可用
- 从页表中去除虚拟地址所在的页表项(将P位置0)
- 在虚拟内存池位图中标记对应页为可用
实现如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
static void _pm_free_page(uint32_t pg_phy_addr)
{
struct _pm_pool* mem_pool;
uint32_t bit_idx = 0;
if(pg_phy_addr >= user_pm.paddr_start)
{
mem_pool = &user_pm;
bit_idx = (pg_phy_addr - user_pm.paddr_start) / PG_SIZE;
}else{
mem_pool = &kernel_pm;
bit_idx = (pg_phy_addr - kernel_pm.paddr_start) / PG_SIZE;
}
_set_bitmap(&mem_pool->pool_bitmap, bit_idx, 0);
}
static void _pt_remove_page(uint32_t vaddr)
{
uint32_t* pte = pte_ptr(vaddr);
*pte &= ~PG_P_1;
asm volatile("invlpg %0" : : "m"(vaddr) : "memory");
}
static void _free_pages_vaddr(_mem_pool_flag pf, void* _vaddr, uint32_t pg_cnt)
{
uint32_t bit_idx_start = 0, vaddr = (uint32_t)_vaddr, cnt = 0;
if(pf == PF_KERNEL)
{
bit_idx_start = (vaddr - kernel_vm.vaddr_start) / PG_SIZE;
while(cnt < pg_cnt)
{
_set_bitmap(&kernel_vm.pool_bitmap, bit_idx_start + cnt, 0);
cnt++;
}
}else{
struct _task_struct* cur_thread = running_thread();
bit_idx_start = (vaddr - cur_thread->user_vm.vaddr_start) / PG_SIZE;
while(cnt < pg_cnt)
{
_set_bitmap(&cur_thread->user_vm.pool_bitmap, bit_idx_start + cnt, 0);
cnt++;
}
}
}
void _vm_free_pages(_mem_pool_flag pf, void* _vaddr, uint32_t pg_cnt)
{
uint32_t pg_phy_addr;
uint32_t vaddr = (int32_t)_vaddr, page_cnt = 0;
ASSERT(pg_cnt >= 1 && vaddr % PG_SIZE == 0);
pg_phy_addr = vaddr2paddr(vaddr);
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= 0x102000);
if(pg_phy_addr >= user_pm.paddr_start)
{
vaddr -= PG_SIZE;
while(page_cnt < pg_cnt)
{
vaddr += PG_SIZE;
pg_phy_addr = vaddr2paddr(vaddr);
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= user_pm.paddr_start);
_pm_free_page(pg_phy_addr);
_pt_remove_page(vaddr);
page_cnt++;
}
_free_pages_vaddr(pf, _vaddr, pg_cnt);
}else{
vaddr -= PG_SIZE;
while(page_cnt < pg_cnt)
{
vaddr += PG_SIZE;
pg_phy_addr = vaddr2paddr(vaddr);
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr < user_pm.paddr_start);
_pm_free_page(pg_phy_addr);
_pt_remove_page(vaddr);
page_cnt++;
}
_free_pages_vaddr(pf, _vaddr, pg_cnt);
}
}
|
其次就是在当前基础上实现 malloc 和 free 系统调用,实现更细化的堆内存管理。内核中的堆内存管理机制和 glibc 的用户 ptmalloc2 堆管理机制并不是一回事。但处理方式和实现机制是类似相通的。
如下定义好内存块 chunk 和 arena 使用的内存块描述符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
struct chunk{
struct list_elem free_elem;
};
struct _chunk_desc{
uint32_t chunk_size;
uint32_t chunks_per_arena;
struct list free_list;
};
struct arena{
struct _chunk_desc* desc;
uint32_t cnt;
bool large;
};
struct _chunk_desc ChunkDescs[DESC_CNT];
|
一种 arena 对应一个 size 的 chunk,内存块描述符 与 arena 是一对多的关系,专门处理对这个 size 的内存块的申请。可用的 chunk 都记录在 free_list 中。每次申请就查 ChunkDescs 中符合要求的 _chunk_desc,如果其 free_list 空了,就创建一个新的 arena,然后从中分配。arena 示例内存结构如下

对于小 size ,一个 arena 就是一页,除去元信息后从剩余部分划分好 chunk。
对于大 size 的申请,arena 只是放在所分配连续页的起始处,1 个 arena 可能对应多页,虽然走分配页的逻辑,但仍然兼容 arena 接口:在大于 1024 字节的分配路径中,除了 arena 元信息和用户请求的 size 之外,按页对齐产生的剩余空间没有被进一步利用,因此形成了内部碎片,但是换来了高效的申请与释放。
如下实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
|
static struct chunk* arena2chunk(struct arena* a, uint32_t idx)
{
return (struct chunk*) ((uint32_t)a + sizeof(struct arena) + idx * a->desc->chunk_size);
}
static struct arena* chunk2arena(struct chunk* b)
{
return (struct arena*)((uint32_t)b & 0xfffff000);
}
void* sys_malloc(uint32_t size)
{
_mem_pool_flag PF;
struct _pm_pool* mem_pool;
uint32_t pool_size;
struct _chunk_desc* descs;
struct _task_struct* cur_thread = running_thread();
if(cur_thread->pgdir == NULL)
{
PF = PF_KERNEL;
pool_size = kernel_pm.pool_size;
mem_pool = &kernel_pm;
descs = ChunkDescs;
}else{
PF = PF_USER;
pool_size = user_pm.pool_size;
mem_pool = &user_pm;
descs = cur_thread->user_chunkdescs;
}
if(!(size > 0 && size < pool_size)) return NULL;
struct arena* a;
struct chunk* b;
lock_acquire(&mem_pool->lock);
if(size > 1024)
{
uint32_t page_cnt = DIV_ROUND_UP(size + sizeof(struct arena), PG_SIZE);
a = _vm_alloc_pages(PF, page_cnt);
if(a != NULL)
{
memset(a, 0, page_cnt * PG_SIZE);
a->desc = NULL;
a->cnt = page_cnt;
a->large = true;
lock_release(&mem_pool->lock);
return (void*)(a + 1);
}else{
lock_release(&mem_pool->lock);
return NULL;
}
}else{
uint8_t desc_idx;
for(desc_idx = 0; desc_idx < DESC_CNT; desc_idx++)
{
if(size <= descs[desc_idx].chunk_size) break;
}
if(list_empty(&descs[desc_idx].free_list))
{
a = _vm_alloc_pages(PF, 1);
if(a == NULL)
{
lock_release(&mem_pool->lock);
return NULL;
}
memset(a, 0, PG_SIZE);
a->desc = &descs[desc_idx];
a->large = false;
a->cnt = descs[desc_idx].chunks_per_arena;
uint32_t chunk_idx;
_intr_status old_status = _disable_intr();
for(chunk_idx = 0; chunk_idx < descs[desc_idx].chunks_per_arena; chunk_idx++)
{
b = arena2chunk(a, chunk_idx);
ASSERT(!elem_find(&a->desc->free_list, &b->free_elem));
list_append(&a->desc->free_list, &b->free_elem);
}
_set_intr_status(old_status);
}
b = elem2entry(struct chunk, free_elem, list_pop(&(descs[desc_idx].free_list)));
memset(b, 0, descs[desc_idx].chunk_size);
a = chunk2arena(b);
a->cnt--;
lock_release(&mem_pool->lock);
return (void*)b;
}
}
void sys_free(void* ptr)
{
ASSERT(ptr != NULL);
if(ptr != NULL)
{
_mem_pool_flag PF;
struct _pm_pool* mem_pool;
if(running_thread()->pgdir == NULL)
{
ASSERT((uint32_t)ptr > K_HEAP_START);
PF = PF_KERNEL;
mem_pool = &kernel_pm;
}else{
PF = PF_USER;
mem_pool = &user_pm;
}
lock_acquire(&mem_pool->lock);
struct chunk* b = ptr;
struct arena* a = chunk2arena(b);
ASSERT(a->large == 0 || a->large == 1);
if(a->desc == NULL && a->large == true)
{
_vm_free_pages(PF, a, a->cnt);
}else{
ASSERT(!elem_find(&a->desc->free_list, &b->free_elem));
if(elem_find(&a->desc->free_list, &b->free_elem))
{
PANIC("double free!");
}
list_append(&a->desc->free_list, &b->free_elem);
a->cnt++;
if(a->cnt == a->desc->chunks_per_arena)
{
uint32_t chunk_idx;
for(chunk_idx = 0; chunk_idx < a->desc->chunks_per_arena; chunk_idx++)
{
struct chunk* b = arena2chunk(a, chunk_idx);
ASSERT(elem_find(&a->desc->free_list, &b->free_elem));
list_remove(&b->free_elem);
}
_vm_free_pages(PF, a, 1);
}
}
lock_release(&mem_pool->lock);
}
}
|
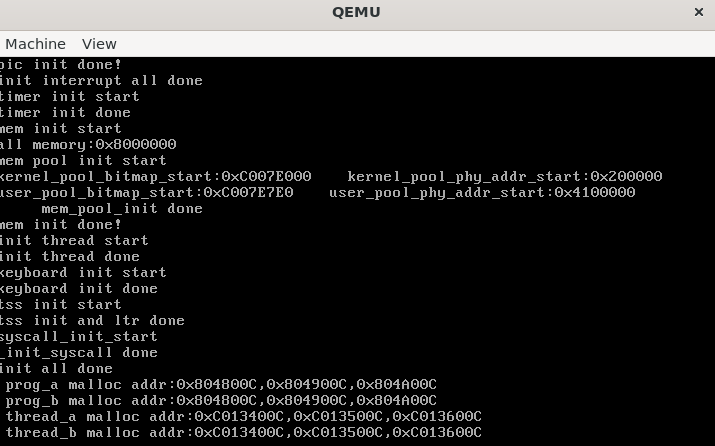
0x03 测试
另外实现了用户使用的 printf ,不多赘述
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| #include "init.h"
#include "debug.h"
#include "stdtype.h"
#include "interrupt.h"
#include "memory.h"
#include "thread.h"
#include "console.h"
#include "kernel/print.h"
#include "keyboard.h"
#include "kernel/ioqueue.h"
#include "process.h"
#include "user/syscall.h"
#include "syscall-init.h"
#include "stdio.h"
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int main(void)
{
print("kernel made by r3t2\n");
init();
process_execute(u_prog_a, "user_prog_a");
process_execute(u_prog_b, "user_prog_b");
thread_create("testA", 31, k_thread_a, NULL);
thread_create("testB", 31, k_thread_b, NULL);
_enable_intr();
while(1);
return 0;
}
void k_thread_a(void* arg)
{
(void)arg;
void* p1 = sys_malloc(0x100);
void* p2 = sys_malloc(0x101);
void* p3 = sys_malloc(0x450);
printf(" thread_a malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(p1);
sys_free(p2);
sys_free(p3);
while(1);
}
void k_thread_b(void* arg)
{
(void)arg;
void* p1 = sys_malloc(0x100);
void* p2 = sys_malloc(0x101);
void* p3 = sys_malloc(0x450);
printf(" thread_b malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(p1);
sys_free(p2);
sys_free(p3);
while(1);
}
void u_prog_a(void)
{
void* p1 = malloc(0x100);
void* p2 = malloc(0x101);
void* p3 = malloc(0x450);
printf(" prog_a malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(p1);
free(p2);
free(p3);
while(1);
}
void u_prog_b(void)
{
void* p1 = malloc(0x100);
void* p2 = malloc(0x101);
void* p3 = malloc(0x450);
printf(" prog_b malloc addr:0x%x,0x%x,0x%x\n", (int)p1, (int)p2, (int)p3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(p1);
free(p2);
free(p3);
while(1);
}
|
如下