0x00 终于实现到用户进程了
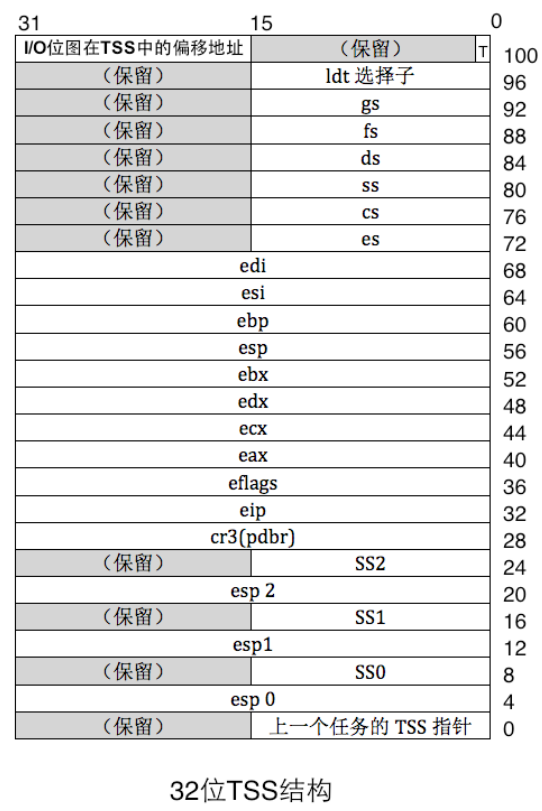
0x01 TSS 简介 在 x86 里,CPU 确实原生支持通过 TSS(Task State Segment)进行“硬件任务切换” ,但现代主流操作系统基本不用它来做真正的任务切换。
TSS 正如其名字,是一个段也就是一片内存区域,CPU 有一个专门的 TR 寄存器来存储 TSS 描述符,如下
可以看到 TSS 是通过选择子来访问的,并且其描述符也存储在GDT中。将 TSS 加载到寄存器 TR 的 指令是 ltr,也就是说 TSS 由用户提供,由 CPU 自动维护。
那么我们要使用它来实现我们的进程任务切换吗?
在每一次任务切换过程中,CPU 除了做特权级检查外,还要在 TSS 的加载、保存、设置 B 位,以及设置标志寄存器 eflags 的 NT 位诸多方面消耗很多精力
一个任务需要单独关联一个 TSS,TSS 需要在 GDT 中注册,GDT 中最多支持 8192 个描述符, 为了支持更多的任务,随着任务的增减,要及时修改 GDT,在其中增减 TSS 描述符,修改过后还要重新 加载 GDT。这种频繁修改描述符表的操作很消耗 CPU 资源
可以看到 TSS 结构中大部分内容都似曾相识:确实,我们在实现内核线程的时候,有一个中断栈结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct _intr_stack { uint32_t vec; uint32_t edi; uint32_t esi; uint32_t ebp; uint32_t esp_dummy; uint32_t ebx; uint32_t edx; uint32_t ecx; uint32_t eax; uint32_t gs; uint32_t fs; uint32_t es; uint32_t ds; uint32_t err_code; void (*eip) (void ); uint32_t cs; uint32_t eflags; void * esp; uint32_t ss; };
已经囊括了 TSS 中大部分内容。
既然如此,我们可以完全抛弃 TSS 了……吗?
还记得,在用户模式下发生中断,CPU 会由低特权级进入高特权级,这会发生栈的切换。当一个中断发生在用户模式(特权级 3),处理器从当前 TSS 的 SS0 和 esp0 成员中获 取用于处理中断的栈。(我们之前写中断处理程序时,没有实现 TSS 也没有维护内核栈,因为我们此前本来就一直都在内核空间)
既然现在我们要实现用户进程,为了维护内核栈,我们还是必须使用 TSS,但不必维护其中的其他成员了,由中断过程来为我们实现它们的上下文保存和切换。换句话说,我们使用 TSS 唯一的理由是为 0 特权级的任务提供栈。(我们效仿 Linux 只使用特权级0和特权级3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #define GDT_VADDR 0xc0000908 struct tss { uint32_t backlink; uint32_t * esp0; uint32_t ss0; uint32_t * esp1; uint32_t ss1; uint32_t * esp2; uint32_t ss2; uint32_t cr3; uint32_t (*eip) (void ); uint32_t eflags; uint32_t eax; uint32_t ecx; uint32_t edx; uint32_t ebx; uint32_t esp; uint32_t ebp; uint32_t esi; uint32_t edi; uint32_t es; uint32_t cs; uint32_t ss; uint32_t ds; uint32_t fs; uint32_t gs; uint32_t ldt; uint32_t trace; uint32_t io_base; }; static struct tss tss ;void update_tss_esp (struct _task_struct* pthread) { tss.esp0 = (uint32_t *)((uint32_t )pthread + PG_SIZE); } static struct _gdt_desc make_gdt_desc (uint32_t * desc_addr, uint32_t limit, uint8_t attr_low, uint8_t attr_high) { uint32_t desc_base = (uint32_t )desc_addr; struct _gdt_desc desc ; desc.limit_low_word = limit & 0x0000ffff ; desc.base_low_word = desc_base & 0x0000ffff ; desc.base_mid_byte = ((desc_base & 0x00ff0000 ) >> 16 ); desc.attr_low_byte = (uint8_t )(attr_low); desc.limit_high_attr_high = ((limit & 0x000f0000 )>>16 ) + (uint8_t )(attr_high); desc.base_high_byte = desc_base >> 24 ; return desc; } void _init_tss(void ){ print("tss init start\n" ); uint32_t tss_size = sizeof (tss); memset (&tss, 0 , tss_size); tss.ss0 = SELECTOR_K_STACK; tss.io_base = tss_size; *((struct _gdt_desc*)(GDT_VADDR+4 *8 )) = make_gdt_desc((uint32_t *)&tss, tss_size - 1 , TSS_ATTR_LOW, TSS_ATTR_HIGH); *((struct _gdt_desc*)(GDT_VADDR+5 *8 )) = make_gdt_desc((uint32_t *)0 , 0xfffff , GDT_CODE_ATTR_LOW_DPL3, GDT_ATTR_HIGH); *((struct _gdt_desc*)(GDT_VADDR+6 *8 )) = make_gdt_desc((uint32_t *)0 , 0xfffff , GDT_DATA_ATTR_LOW_DPL3, GDT_ATTR_HIGH); uint64_t gdt_operand = ((8 *7 -1 ) | ((uint64_t )(uint32_t )GDT_VADDR << 16 )); asm volatile ("lgdt %0" : : "m" (gdt_operand)) ; asm volatile ("ltr %w0" : : "r" (SELECTOR_TSS)) ; print("tss init and ltr done\n" ); }
0x02 用户内存管理 尽然已经实现了内核线程,内存申请时应该上锁,给物理内存池加一个锁成员。
1 2 3 4 5 6 7 struct _pm_pool { struct bitmap pool_bitmap ; uint32_t paddr_start; uint32_t pool_size; struct lock lock ; };
虚拟内存池就不加锁成员了(这里的虚拟内存更多指的是虚拟地址),因为各个进程拥有独立虚拟内存,不会互相影响。就算是内核线程,我们在三个对外的内存申请接口函数加锁,其内部才访问虚拟内存池,所以也可保证安全。
然后增加用户内存的管理,和内核内存管理大同小异。修改或者增加的函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 static void * _get_pages_vaddr(_mem_pool_flag pf, uint32_t pg_cnt){ int vaddr_start = 0 , bit_idx_start = -1 ; uint32_t cnt = 0 ; if (pf == PF_KERNEL) { bit_idx_start = _scan_bitmap(&kernel_vm.pool_bitmap, pg_cnt); if (bit_idx_start == -1 ) return NULL ; while (cnt < pg_cnt) { _set_bitmap(&kernel_vm.pool_bitmap, bit_idx_start + cnt, 1 ); cnt++; } vaddr_start = kernel_vm.vaddr_start + bit_idx_start * PG_SIZE; }else { struct _task_struct* cur = running_thread(); bit_idx_start = _scan_bitmap(&cur->user_vm.pool_bitmap, pg_cnt); if (bit_idx_start == -1 ) return NULL ; while (cnt < pg_cnt) { _set_bitmap(&cur->user_vm.pool_bitmap, bit_idx_start + cnt, 1 ); cnt++; ASSERT((uint32_t )vaddr_start < (0xc0000000 - PG_SIZE)); } vaddr_start = cur->user_vm.vaddr_start + bit_idx_start * PG_SIZE; } return (void *)vaddr_start; } static void * _pm_alloc_page(struct _pm_pool* m_pool){ int bit_idx = _scan_bitmap(&m_pool->pool_bitmap, 1 ); if (bit_idx == -1 ) return NULL ; _set_bitmap(&m_pool->pool_bitmap, bit_idx, 1 ); uint32_t page_paddr = ((bit_idx * PG_SIZE) + m_pool->paddr_start); return (void *)page_paddr; } static void _pt_map_page(void * _vaddr, void * _page_paddr){ uint32_t vaddr = (uint32_t )_vaddr, page_paddr = (uint32_t )_page_paddr; uint32_t * pde = pde_ptr(vaddr); uint32_t * pte = pte_ptr(vaddr); if (*pde & 0x00000001 ) { ASSERT(!(*pte & 0x00000001 )); if (!(*pte & 0x00000001 )) { *pte = (page_paddr | PG_US_U | PG_RW_W | PG_P_1); }else { PANIC("pte repeat" ); *pte = (page_paddr | PG_US_U | PG_RW_W | PG_P_1); } }else { uint32_t pde_paddr = (uint32_t )_pm_alloc_page(&kernel_pm); *pde = (pde_paddr | PG_US_U | PG_RW_W | PG_P_1); memset ((void *)((uint32_t )pte & 0xfffff000 ), 0 , PG_SIZE); ASSERT(!(*pte & 0x00000001 )); *pte = (page_paddr | PG_US_U | PG_RW_W | PG_P_1); } } static void * _vm_alloc_pages(_mem_pool_flag pf, uint32_t pg_cnt){ ASSERT(pg_cnt > 0 && pg_cnt < 32512 ); void * vaddr_start = _get_pages_vaddr(pf, pg_cnt); if (vaddr_start == NULL ) return NULL ; uint32_t vaddr = (uint32_t )vaddr_start, cnt = pg_cnt; struct _pm_pool * mem_pool = while (cnt > 0 ) { void * page_paddr = _pm_alloc_page(mem_pool); if (page_paddr == NULL ) return NULL ; _pt_map_page((void *)vaddr, page_paddr); vaddr += PG_SIZE; cnt--; } return vaddr_start; } void * map_page (_mem_pool_flag pf, uint32_t vaddr) { struct _pm_pool * mem_pool = lock_acquire(&mem_pool->lock); struct _task_struct * cur = int32_t bit_idx = -1 ; if (cur->pgdir != NULL && pf == PF_USER) { bit_idx = (vaddr - cur->user_vm.vaddr_start)/PG_SIZE; ASSERT(bit_idx > 0 ); _set_bitmap(&cur->user_vm.pool_bitmap, bit_idx, 1 ); }else if (cur->pgdir == NULL && pf == PF_KERNEL){ bit_idx = (vaddr - kernel_vm.vaddr_start)/PG_SIZE; ASSERT(bit_idx > 0 ); _set_bitmap(&kernel_vm.pool_bitmap, bit_idx, 1 ); }else { PANIC("map_page:not allow kernel alloc userspace or user alloc kernelspace by map_page" ); } void * paddr = _pm_alloc_page(mem_pool); if (paddr == NULL ) { lock_release(&mem_pool->lock); return NULL ; } _pt_map_page((void *)vaddr, paddr); lock_release(&mem_pool->lock); return (void *)vaddr; } void * alloc_kernel_pages (uint32_t pg_cnt) { lock_acquire(&kernel_pm.lock); void * vaddr = _vm_alloc_pages(PF_KERNEL, pg_cnt); if (vaddr != NULL ) memset (vaddr, 0 , pg_cnt * PG_SIZE); lock_release(&kernel_pm.lock); return vaddr; } void * alloc_user_pages (uint32_t pg_cnt) { lock_acquire(&user_pm.lock); void * vaddr = _vm_alloc_pages(PF_USER, pg_cnt); if (vaddr != NULL ) memset (vaddr, 0 , pg_cnt * PG_SIZE); lock_release(&user_pm.lock); return vaddr; } uint32_t vaddr2paddr (uint32_t vaddr) { uint32_t * pte = pte_ptr(vaddr); return ((*pte & 0xfffff000 ) + (vaddr & 0x00000fff )); }
0x03 如何创建用户进程 0x01 进入用户态 用户进程当然是在用户态运行,特权级是3。还记得,唯一一种处理器会从高特权降到低特权运行的情况:处理器从中断处理程序中返回到用户态的时候 。但我们现在要创建用户进程,谈何从中断“返回”用户态呢?
其实没那么玄乎,既然没有用户进程,那我们自己伪造一下中断栈的内容,并创建 TSS 保存好内核栈,然后跳转到中断结束处,自然就可以“返回”用户态了。也就是说,创建用户进程时,我们先创建一个内核线程,让它做好创建用户进程所需的初始化工作,并跳转到中断处理程序结束返回的地方,就顺理成章进入了用户态,运行用户程序了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void process_init (void * filename_) { void * function = filename_; struct _task_struct * cur = cur->self_kstack = (uint32_t *)((uint8_t *)cur->self_kstack + sizeof (struct _thread_stack)); struct _intr_stack * proc_stack =struct _intr_stack*)cur->self_kstack; proc_stack->edi = proc_stack->esi = proc_stack->ebp = proc_stack->esp_dummy = 0 ; proc_stack->ebx = proc_stack->edx = proc_stack->ecx = proc_stack->eax = 0 ; proc_stack->gs = 0 ; proc_stack->ds = proc_stack->es = proc_stack->fs = SELECTOR_U_DATA; proc_stack->eip = function; proc_stack->cs = SELECTOR_U_CODE; proc_stack->eflags = (EFLAGS_IOPL_0 | EFLAGS_MBS | EFLAGS_IF_1); proc_stack->esp = (void *)((uint32_t )map_page(PF_USER, USER_STACK3_VADDR) + PG_SIZE); proc_stack->ss = SELECTOR_U_DATA; asm volatile ("movl %0, %%esp\n\tjmp intr_exit" : : "g" (proc_stack) : "memory" ) ; }
创建进程的内核线程操作如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void process_execute (void * filename, char * threadname) { struct _task_struct * thread =1 ); thread_init_info(thread, threadname, default_prio); create_user_vaddr_bitmap(thread); thread_init_stack(thread, process_init, filename); thread->pgdir = create_page_dir(); _intr_status old_status = _disable_intr(); ASSERT(!elem_find(&thread_ready_list, &thread->general_tag)); list_append(&thread_ready_list, &thread->general_tag); ASSERT(!elem_find(&thread_all_list, &thread->all_list_tag)); list_append(&thread_all_list, &thread->all_list_tag); _set_intr_status(old_status); }
0x02 独立虚拟地址空间 还记得每个用户进程享有独立的虚拟地址空间,我们需要为每个用户进程都创建二级页表(包括页目录表和页表)。
此前在 loader 时就用汇编实现过创建页表的过程,所以不必过多赘述。值得注意的是所有用户进程共享内核地址空间,所以页目录表中内核空间的表项全部直接从内核的页目录表中复制即可。
另外,每个用户进程的虚拟内存也需要虚拟内存池来管理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 void activate_page_dir (struct _task_struct* p_thread) { uint32_t pagedir_phy_addr = 0x100000 ; if (p_thread->pgdir != NULL ) { pagedir_phy_addr = vaddr2paddr((uint32_t )p_thread->pgdir); } asm volatile ("movl %0, %%cr3" : : "r" (pagedir_phy_addr) : "memory" ) ; } uint32_t * create_page_dir (void ) { uint32_t * page_dir_vaddr = alloc_kernel_pages(1 ); if (page_dir_vaddr == NULL ) { console_put("create_page_dir : alloc_kernel_page failed!" ); return NULL ; } memcpy ((uint32_t *)((uint32_t )page_dir_vaddr + 0x300 *4 ), (uint32_t *)(0xfffff000 + 0x300 *4 ), 1024 ); uint32_t new_page_dir_phy_addr = vaddr2paddr((uint32_t )page_dir_vaddr); page_dir_vaddr[1023 ] = new_page_dir_phy_addr | PG_US_U | PG_RW_W | PG_P_1; return page_dir_vaddr; } void update_pt_tss (struct _task_struct* p_thread) { ASSERT(p_thread != NULL ); activate_page_dir(p_thread); if (p_thread->pgdir) { update_tss_esp(p_thread); } } void create_user_vaddr_bitmap (struct _task_struct* user_prog) { user_prog->user_vm.vaddr_start = USER_VADDR_START; uint32_t bitmap_pg_cnt = DIV_ROUND_UP((0xc0000000 - USER_VADDR_START)/PG_SIZE/8 , PG_SIZE); user_prog->user_vm.pool_bitmap.bits = alloc_kernel_pages(bitmap_pg_cnt); user_prog->user_vm.pool_bitmap.bytes_len = (0xc0000000 - USER_VADDR_START)/PG_SIZE/8 ; _init_bitmap(&user_prog->user_vm.pool_bitmap); }
0x03 总流程 1 2 3 4 5 process_create(): 创建一个内核线程 --> 注册thread_start执行的函数为 process_init --> create_user_vaddr_bitmap() 创建用户页表 --> 将创建的内核线程加入内核线程队列 时钟中断发生,调度内核线程,执行 process_init(): 将 _task_struct中内核栈指针指向其中断栈,修改中断栈内容 --> jmp intr_exit --> intr_exit(): 根据中断栈信息返回到用户态并执行用户程序 时钟中断发生, 用户程序中断; 下一次再调度创建此用户进程的内核线程时,会保存其内核栈,更新到用户页表,再次返回到用户态,执行用户程序
注意任务调度函数要增加一个 process_activate(next);,来更新页表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void task_schedule (void ) { ASSERT(_get_intr_status() == INTR_OFF); struct _task_struct * cur = if (cur->status == TASK_RUNNING) { ASSERT(!elem_find(&thread_ready_list, &cur->general_tag)); list_append(&thread_ready_list, &cur->general_tag); cur->ticks = cur->priority; cur->status = TASK_READY; }else { } ASSERT(!list_empty(&thread_ready_list)); thread_tag = NULL ; thread_tag = list_pop(&thread_ready_list); struct _task_struct * next =struct _task_struct, general_tag, thread_tag); next->status = TASK_RUNNING; update_pt_tss(next); switch_task(cur, next); }
0x04 测试 main.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include "init.h" #include "debug.h" #include "stdtype.h" #include "interrupt.h" #include "memory.h" #include "thread.h" #include "console.h" #include "kernel/print.h" #include "keyboard.h" #include "kernel/ioqueue.h" #include "process.h" void k_thread_a (void *) ; void k_thread_b (void *) ;void u_prog_a (void ) ;void u_prog_b (void ) ;volatile int test_var_a = -1 , test_var_b = -1 ;int main (void ) { print("kernel made by r3t2\n" ); init(); thread_create("testB" , 31 , k_thread_b, NULL ); thread_create("testA" , 31 , k_thread_a, NULL ); process_execute(u_prog_a, "user_prog_a" ); process_execute(u_prog_b, "user_prog_b" ); _enable_intr(); while (1 ); return 0 ; } void k_thread_a (void * arg) { while (1 ) { console_put("v_a:" ); console_put(test_var_a); console_put(" " ); } } void k_thread_b (void * arg) { while (1 ) { console_put("v_b:" ); console_put(test_var_b); console_put(" " ); } } void u_prog_a (void ) { while (1 ) { test_var_a++; } } void u_prog_b (void ) { while (1 ) { test_var_b++; } }
可能会有疑问,定义的 u_prog_a 和 u_prog_b也是内核函数,怎么能用来模拟用户程序呢?同时这里的全局变量也在内核区域,用户进程如何能访问呢?
我们还没有实现文件系统,所以姑且用函数来模拟,反生加载用户程序后也是执行函数。
注意我们在初始化 tss 的时候顺便
1 2 3 *((struct _gdt_desc*)(GDT_VADDR+5 *8 )) = make_gdt_desc((uint32_t *)0 , 0xfffff , GDT_CODE_ATTR_LOW_DPL3, GDT_ATTR_HIGH); *((struct _gdt_desc*)(GDT_VADDR+6 *8 )) = make_gdt_desc((uint32_t *)0 , 0xfffff , GDT_DATA_ATTR_LOW_DPL3, GDT_ATTR_HIGH);
准备好了用户数据段和用户代码段描述符,并且覆盖了整个地址空间。也就是说整个地址空间都可描述。
1 2 3 4 5 proc_stack->ds = proc_stack->es = proc_stack->fs = SELECTOR_U_DATA; proc_stack->cs = SELECTOR_U_CODE; #define SELECTOR_U_DATA ((6<<3) + (TI_GDT << 2) + RPL3) #define SELECTOR_U_CODE ((5<<3) + (TI_GDT << 2) + RPL3)
这里设置好了用户进程的 CPL 为 3,我们用指向 DPL 为 3 的段描述符的选择子去访问内核空间,这不符合页表的权限检查,但是符合特权级检查。至于页表的权限检查,记得我们在 loader.S 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ; ==== 开始创建内核地址空间最低4MB的页目录项(PDE) .create_pde: mov eax, PAGE_DIR_TABLE_POS add eax, 0x1000 ;页目录表本身占用0x1000大小,+0x1000就是第一个页表的物理地址 mov ebx, eax ;此处为ebx赋值, 是为.create_pte做准备, ebx为基址 or eax, PG_US_U | PG_RW_W | PG_P ;页目录项的属性RW和P位为1,US为1表示用户属性,所有特权级都可以访问 mov [PAGE_DIR_TABLE_POS + 0x0], eax ;第一个目录项 mov [PAGE_DIR_TABLE_POS + 0xc00], eax ;一个页目录项占用4字节, +0xc00对应第0x300个页目录项 ; 一个页目录项对应一张页表,一张页表大小0x1000字节, 一个页表项4字节, 共记录0x400页, 一页大小也是0x1000 ; 那么第0x300个页目录项也就对应地址 0x300*0x400*0x1000 = 0xc0000000(内核地址的起始) 开始的 4MB 内存 ; 这样0xc03fffff以下的地址和0x003fffff以下的地址都指向相同的页表, 也就使用相同的映射方式, 映射到同一个物理地址 sub eax, 0x1000 mov [PAGE_DIR_TABLE_POS + 4092], eax ;使得最后一个目录项地址指向页目录表自己的地址 ; ==== 开始创建内核地址空间最低1MB对应的页表项(PTE), 实际映射到物理地址最低的1MB mov ecx, 256 ;1M低端内存/每页大小4K = 256, 因为物理地址最低的4MB只使用最低的1MB内存来存放kernel mov esi, 0 ;虚拟地址0x0~0x3fffff和虚拟地址0xc0000000~0xc03fffff对应的物理页,现在只用了低1MB,此时虚拟地址是等于物理地址的 mov edx, PG_US_U | PG_RW_W | PG_P ; 页表属性。注意进入循环前第一页物理地址是0起始,所以直接用属性赋值即可 .create_pte: ;创建Page Table Entry mov [ebx + esi*4], edx ;ebx为第一个页表的首地址,此前已赋值 add edx, 0x1000 ; 下一页 inc esi loop .create_pte
创建时候设置了所有特权级可访问(为了测试用)。所以这里是没有问题的。
回到测试代码,我们还没有实现给用户进程使用的打印函数,并且我们设置了显存段对用户不可访问,所以用户进程是无法打印的:
所以我们单独开内核线程来输出这两个全局变量,确保用户进程运行了。
另外测试过程中发现如果不将两个全局变量声明为 volatile,会被优化掉,debug发现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ❯ nm build/kernel.bin |grep -P 'u_prog|test_var' c0005164 D test_var_a c0005160 D test_var_b c0001500 T u_prog_a c0001510 T u_prog_b ... pwndbg> b *0xc0001500 Breakpoint 1 at 0xc0001500 pwndbg> c Continuing. Breakpoint 1, 0xc0001500 in ?? () Permission error when attempting to parse page tables with gdb-pt-dump. Either change the kernel-vmmap setting, re-run GDB as root, or disable `ptrace_scope` (`echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope`) Exception occurred: context: 'NoneType' object has no attribute 'markers' (<class 'AttributeError' >) For more info invoke `set exception-verbose on` and rerun the command or debug it by yourself with `set exception-debugger on` pwndbg> x/i 0xc0001500 => 0xc0001500: jmp 0xc0001500
可以看到函数被优化成了单纯的死循环。所以加上 volatile。
最后效果如下
这里因为窗口大小限制以及大量输出滚屏,只看到了 b 的输出,调换一下 a b 线程的创建顺序就可以看到 a 的输出了